repmgr is a suite of open-source tools to manage replication and failover within a cluster of PostgreSQL servers. It enhances PostgreSQL's built-in replication capabilities with utilities to set up standby servers, monitor replication, and perform administrative tasks such as failover or switchover operations.
repmgr 4 is a complete rewrite of the existing repmgr codebase, allowing the use of all of the latest features in PostgreSQL replication.
PostgreSQL 10, 9.6 and 9.5 are fully supported. PostgreSQL 9.4 and 9.3 are supported, with some restrictions.
repmgr is distributed under the GNU GPL 3 and maintained by 2ndQuadrant.
Let's start with installation of of repmgr
I am assuming that you have already install PostgreSQL Server .
Step 1 : -
Download source code of repmgr from below link .
https://github.com/2ndQuadrant/repmgr/archive/master.zip
Step 2 : -




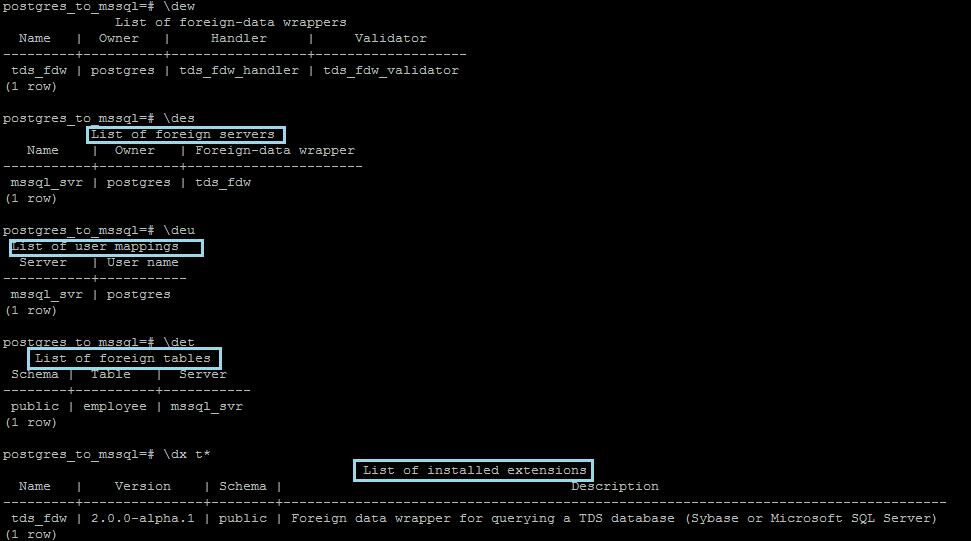
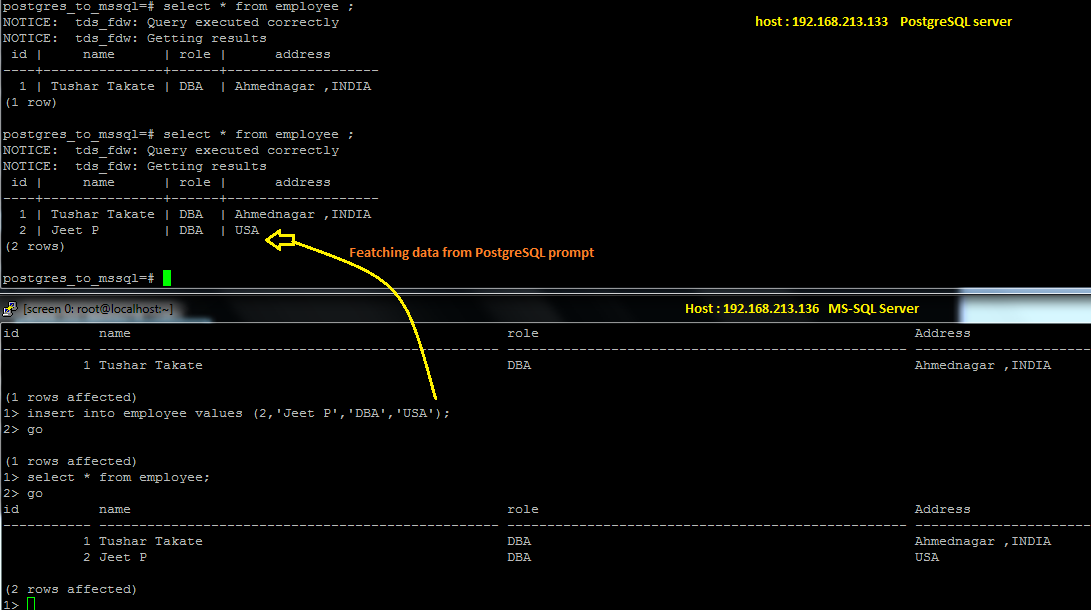
Lets start this server on both server as show in below image .



repmgr 4 is a complete rewrite of the existing repmgr codebase, allowing the use of all of the latest features in PostgreSQL replication.
PostgreSQL 10, 9.6 and 9.5 are fully supported. PostgreSQL 9.4 and 9.3 are supported, with some restrictions.
repmgr is distributed under the GNU GPL 3 and maintained by 2ndQuadrant.
Let's start with installation of of repmgr
I am assuming that you have already install PostgreSQL Server .
Step 1 : -
Download source code of repmgr from below link .
https://github.com/2ndQuadrant/repmgr/archive/master.zip
Step 2 : -
| unzip master.zip cd repmgr-master/ ##Make sure you have configured environment variable for PostgreSQL if not then do it manually as below . export PATH=/usr/local/Postgresql9.6/bin/:$PATH export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/Postgresql9.6/lib/ ./configure --prefix=/usr/local/Postgresql9.6/make make install mkdir /etc/repmgr/chmod 700 -R /etc/repmgr/chown postgres:root -R /etc/repmgr/cp repmgr.conf.sample /etc/repmgr/repmgr.conf |
Step 4 : -
Manage pg_hba.conf and postgresq.conf paramaters which required for replication [I using replication slots]
Create on user for replication and repmgr
create user repmgr superuser ;
create database repmgr with owner repmgr;
create user repmgr superuser ;
create database repmgr with owner repmgr;
Required parameters in postgresql.conf for replication slots
| listen_addresses='*' max_wal_senders = 5 wal_keep_segments = 100 archive_mode = always archive_command = '/bin/true' wal_level = logical hot_standby=on max_replication_slots=5 shared_preload_libraries = 'repmgr' |
-- Restart PostgreSQL service
create on replication slot
SELECT * FROM pg_create_physical_replication_slot('repmgr_test_slot');
Required entries in pg_hba.conf for replication slots
| local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 192.168.1.0/24 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 192.168.1.0/24 trust |
Step 5 : -
Configure/adjust repmger.conf parameters as per need .
repmger.conf is created in step 2 .
node_name = 'Master'
conninfo = 'host=current_host_IP user=repmgr dbname=repmgr'
data_directory=/usr/local/Postgresql9.6/data/
promote_command='/usr/local/Postgresql9.6/bin/repmgr standby promote -f /etc/repmgr/repmgr.conf'
follow_command='/usr/local/Postgresql9.6/bin/repmgr standby follow -f /etc/repmgr/repmgr.conf -W --upstream-node-id=%n'
use_replication_slots = yes
pg_bindir=/usr/local/PostgreSQL9.6/bin #Set this paramater if env varialbe is not set .
log_level=DEBUG
log_facility=STDERR
log_file='/tmp/repmgr.log'
failover=automatic
priority=60
reconnect_attempts=2
reconnect_interval=5
monitoring_history=yes
|
Step 6 :-
Resgister primary/master server with repmgr as shown in below image
/usr/local/Postgresql9.6/bin/repmgr -f /etc/repmgr/repmgr.conf primary register Check schema and status of
Check schema and status of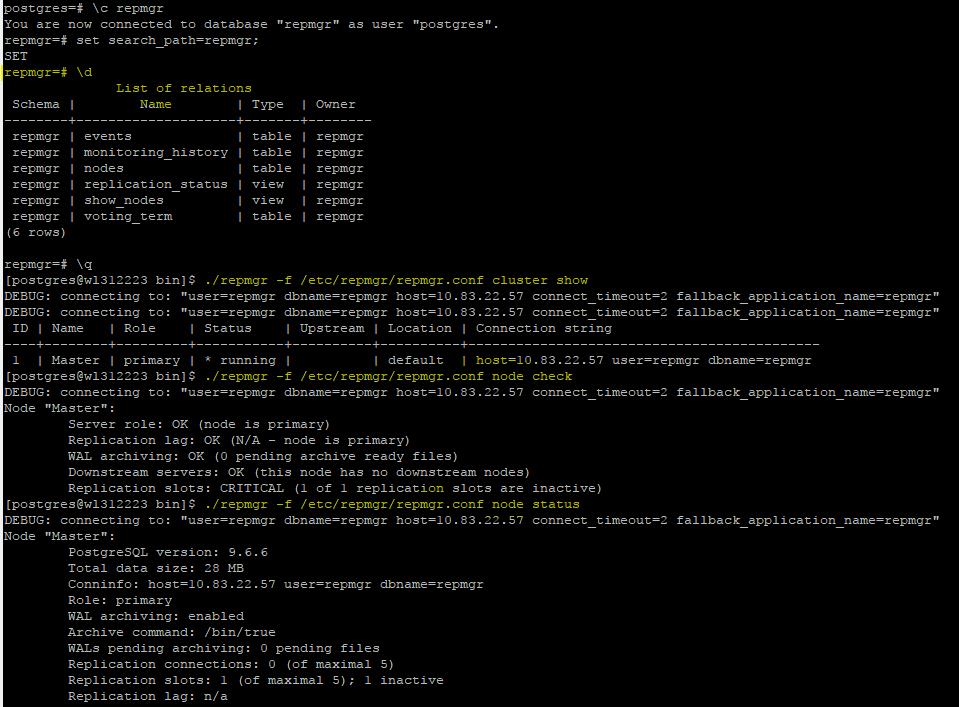
Check schema and status of
Step 7 : -
Install repmgr on slave server as given in step 2 .
Make parameter changes on slave server as given in step 5 .
Create/Build a clone/replica by using repmgr .
/usr/local/Postgresql9.6/bin/repmgr -f /etc/repmgr/repmgr.conf --force -h 10.83.22.57 -d repmgr -U repmgr --verbose standby clone
It will create recovery.conf by it's own .Just verify it once .
Step 8 : -
Start slave/replica server .
Register slave/replica node .
repmgr -f /etc/repmgr/repmgr.conf standby REGISTER
Step 9 : -
Start repmgd daemon to keep server state monitoring .
repmgrd is a management and monitoring daemon which runs on each node in a replication cluster. It can automate actions such as failover and updating standbys to follow the new primary, as well as providing monitoring information about the state of each standby.
Lets start this server on both server as show in below image .
repmgrd -f /etc/repmgr/repmgr.conf --verbose monitoring_history
Note: For permanent operation, we recommend using the options -d/--daemonize to detach the repmgrd process, and -p/--pid-file to write the process PID to a file.
Step 10 : -
Stop master DB service to perform automatic fail-over
repmgrd will start automatic fail-over .
By Taking clone of New primary server you can build new replica .
Step 11 :-
Perform switch-over .
You need to execute switch over command from standby server .
First do dry-run ,Then start switch-over .
repmgr -f /etc/repmgr/repmgr.conf standby SWITCHOVER --siblings-follow --dry-run
repmgr -f /etc/repmgr/repmgr.conf standby SWITCHOVER --siblings-follow
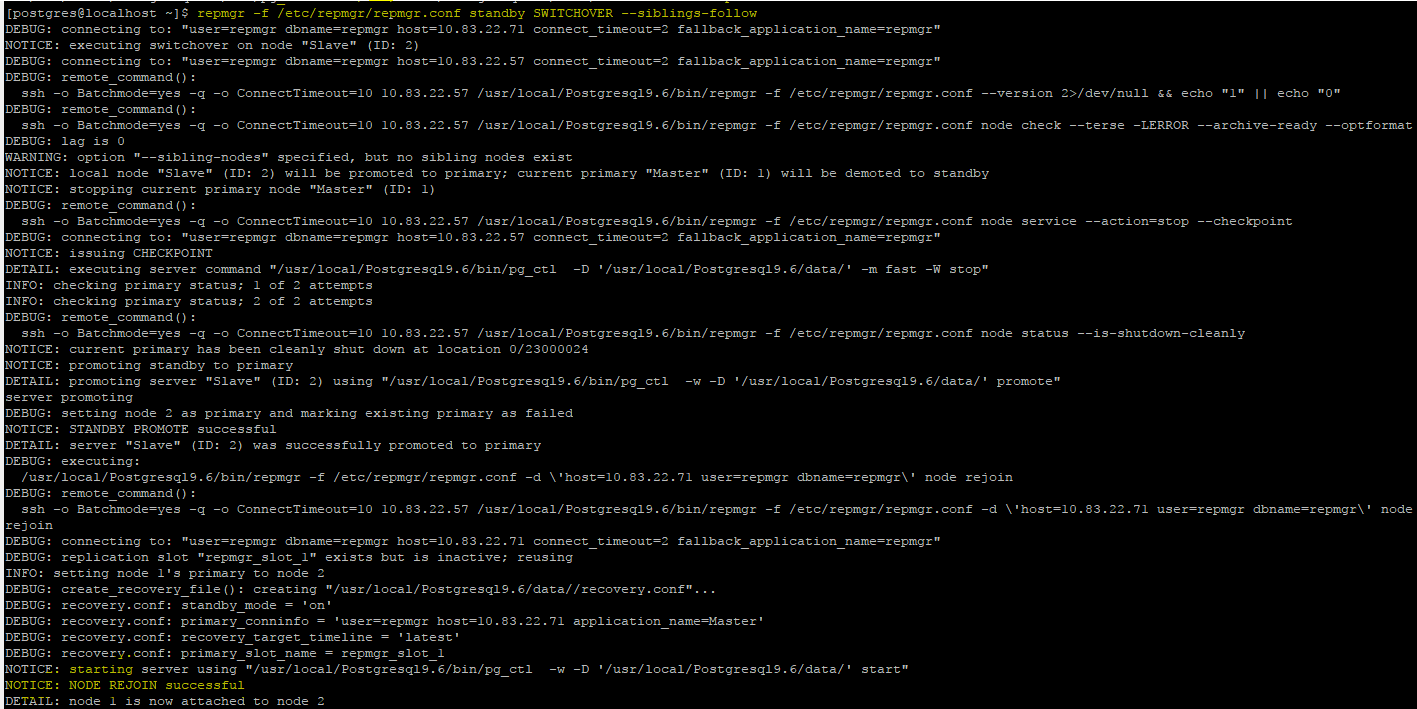


Step 12 :-

Before Switch-over
After Switch-over
Step 12 :-
Node rejoin
While doing switch-over this did't get performed well .My replica server become master but old master did't get .
In that case i want to join this old master as a slave/replica server with my new master server .
Execute this command on that host where server is down.
repmgr -f /etc/repmgr/repmgr.conf node rejoin --force-rewind -d 'host=10.83.22.57 dbname=repmgr user=repmgr'
Host = it is ip address of new primary server .